Predicting Strain Origin From k-mer Counts
In this case study we talk through how we decided on which strain origin locations were used, how we pre-selected certain \(k\)-mers to train our machine learning models on, and finally a discussion on our preliminary results with an analysis of which strain origin locations we see our model performing better.
Data
Our supervised dataset consists of 2,874 paired datapoints collected over the period 2014-2019. Each pair contains a 12,103,121 \(k\)-mer count vector and an associated strain origin string. Since we are interested in predicting the strain origin for a new \(k\)-mer vector, we initially split the data into the periods 2014-2018 (train) and 2019 (validating). At this point we perform a simple analysis of the target origin labels on the training data.
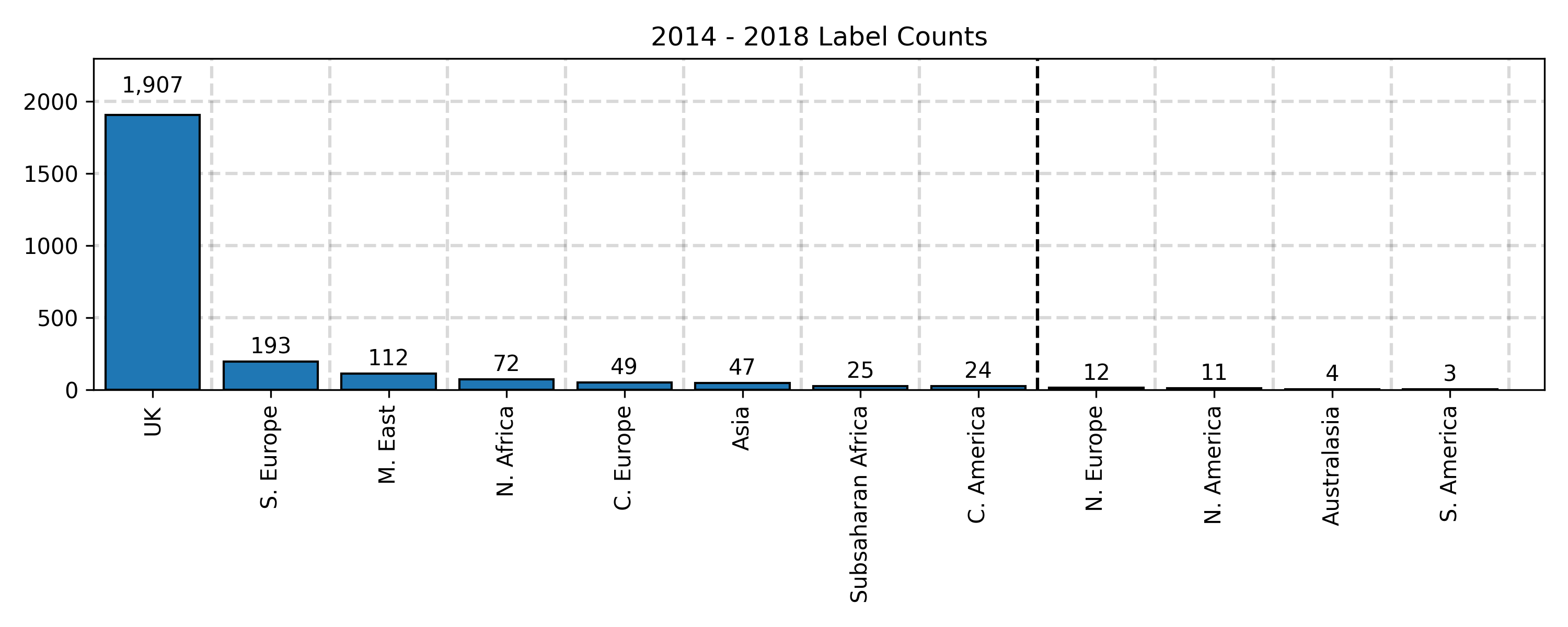
From the above, we can observe that there is a huge imbalance on origin locations with a heavy skew towards strains originating from the UK. Our experimental paradigm was to originally train on the full 2,474 examples gathered over the period 2014 - 2018 and check our predictions against the 415 data points in the 2019 dataset. Since most predictive models perform better when there are more training examples, we decide to omit strain origin labels with a low count. We have decided arbitrarly that strain origin counts less than 20 should be ignored as indicated by the black dashed line.
Feature Selection by Fisher Scores
Since the training data is large (2,474 examples each with 12,103,121 \(k\)-mer counts) it is infeasible to preload it into memory for a model to train on directly. From this point, we motivate the use of feature selection, that is, a way of only using a subset of the \(k\)-mer counts before any machine learning model is used. We decided to use the Fisher Score to help select which features to use. The score for the \(i\)-th feature is computed using the following formula.
where
\(n_j\) is the number of observations belonging to the \(j\)-th class
\(\mu_j\) is the global mean of the \(i\)-th feature
\(\mu_{ij}\) is the mean of the \(i\)-th feature belonging to the \(j\)-th class
\(\sigma_{ij}^2\) is the variance of the \(i\)-th feature belonging to the \(j\)-th class
After computing a score for each feature, we can simply choose to preload the top \(k\) scoring features where we choose \(k\) to be sufficiently small to avoid memory issues.
Experiment
Our experimental design explores how changing a model complexity parameter affects predictive performance when training on our 2014 - 2018 dataset and evaluated against the 2019 dataset. Further, we only focus on the first eight strain origin locations from Figure 1, and we vary the number of \(k\)-mers we preload but still preserving the order computed by the Fisher Scores as previously discussed.
It is important to note the training and evaluation times for machine learning models vary significantly. Below we show the training and evaluation times of the Logisitic Regression and Random Forest models.
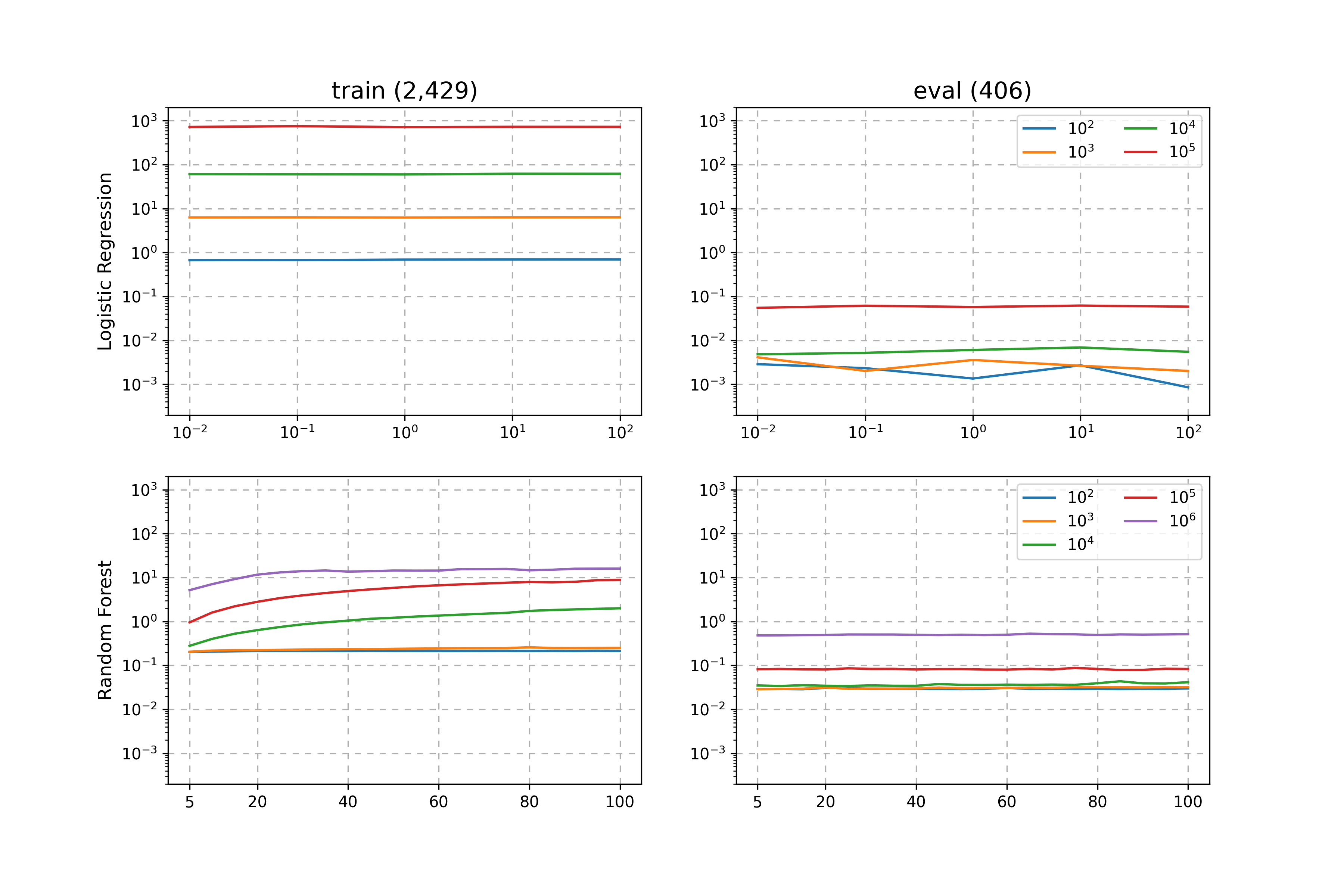
From the above we can see that each time we increase the number of \(k\)-mers by an order of magnitude, so does the training time. Comparing the training times of the models, we observe that the Random Forest scales far better and is significantly faster when we consider a large feature space (when we consider a large number of \(k\)-mers).
Below we show the recall metric for the Random Forest model varying both the number of \(k\)-mers the model could see and the Random Forest complexity parameter maximum depth.
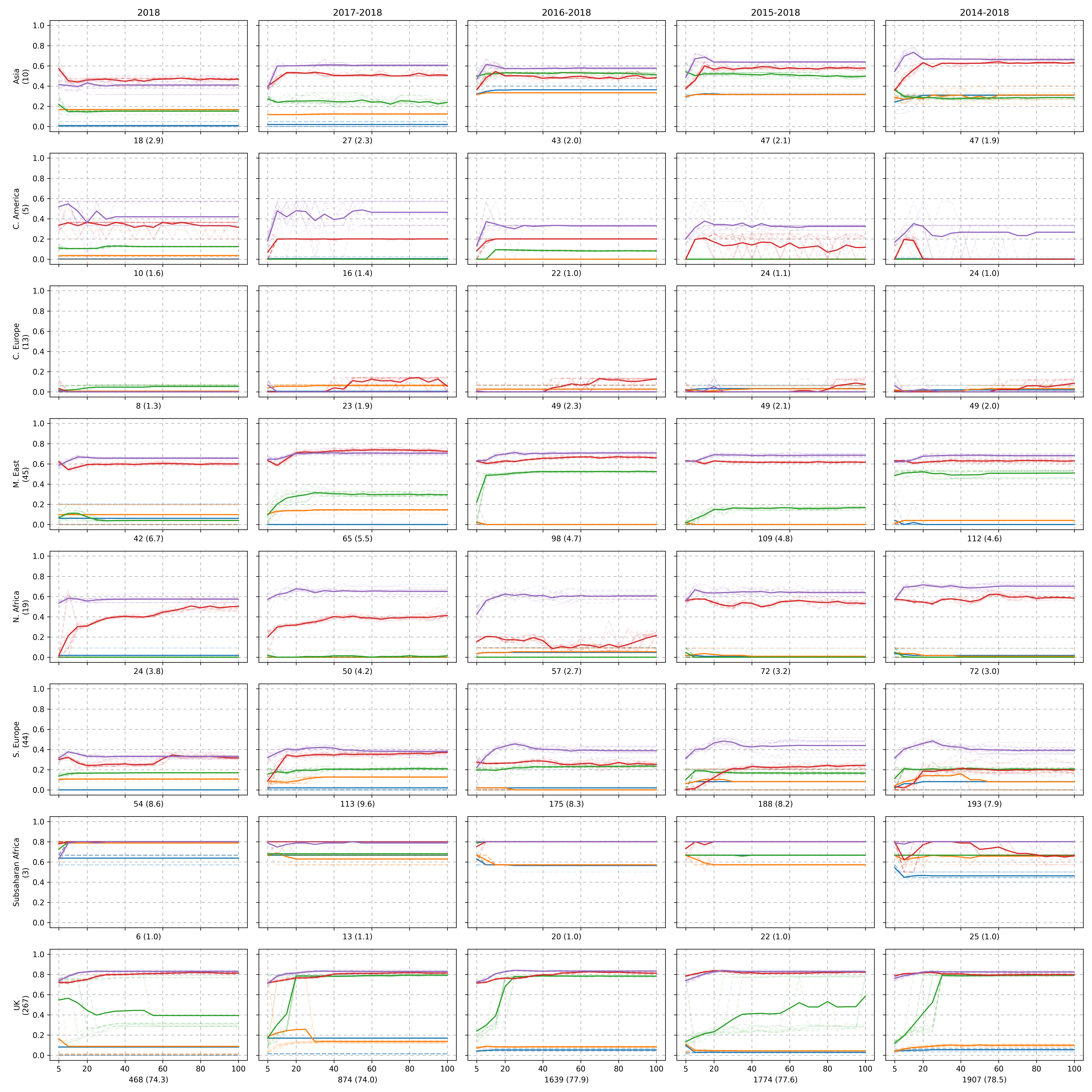
The color scheme for Figure 3 is the same as Figure 2 where each color represents a number of \(k\)-mers used as ranked by the Fisher Scores. Each row refers to a region with the number of test examples present in the year 2019, and each column varies the training data period - this is to observe the effects of having more data. The x-label shows the number of training data points belonging to the region row and the column period as well as the associated proportion for that period. Each experiment was conducted ten times where each trial is visualised as a faded dashed line. The solid line is the average of the ten trials.
We can see that there is a significant class imbalance issue whereby the number of training examples for each region vary significantly and or not uniform. Despite this, we can see that some regions outperform others even when the number of training examples is lower. Consider the regions M. East, and S. Europe for the training period 2014 - 2018. We observe that has less training examples but achieves a much better set of recall evaluations. This may be because certain regions of the world could be more distinct than others due to population genetics, imported food etc.
| Region | No. of Train Instances | F1-Score |
|---|---|---|
| Asia | 47 | 0.66667 |
| C. America | 24 | 0.57143 |
| C. Europe | 49 | 0.13333 |
| M. East | 112 | 0.65487 |
| N. Africa | 72 | 0.68421 |
| S. Europe | 193 | 0.51685 |
| Subsaharan Africa | 25 | 0.80000 |
| UK | 1,907 | 0.83206 |
Note
Our dataset has a huge class imbalance and results may vary across different datasets.